Spring Cloud Gateway内存泄漏排查
背景
线上Spring Cloud Gateway网关运行一段时间后会自动重启。通过Prometheus监控可以观察到现象是内存使用量持续上升
前期排查
前期排查主要使用Arthas获取最忙的线程,观察最忙的线程在做什么。在这一步我们只能获取到与feign的请求有关。 因为我们在网关上做了一层转发,使用的是feign,并不是单独起一个服务来通过route路由来实现的。
在这一步,我们只能获取到这些信息。
后面我在线上机器使用命令转储了一份hprof二进制Heap Dump文件
jmap -dump:live,format=b,file=moatkon_heap.hprof [pid]后面使用MAT工具分析后并未查到具体原因。
验证
既然前面猜测可能与feign调用有关,那就尝试在本地复现。在本地使用Jmeter来并发调用,看能否复现。
Jmeter并发线程数为600,一直循环下去
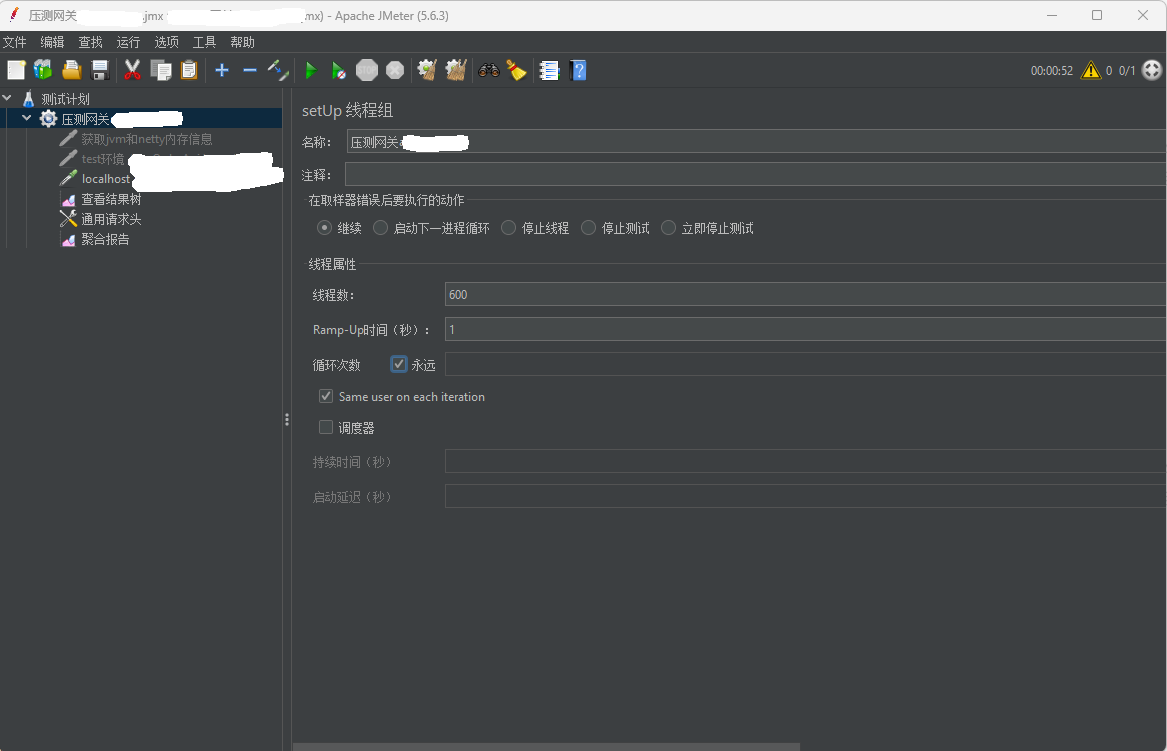
在使用Jmeter并发调用前根据 https://netty.io/wiki/reference-counted-objects.html 这篇文章在本地开启ADVANCED的泄露检测级别
-Dio.netty.leakDetection.level=advanced开启后使用Jmeter开启600个线程来并发调用。刚调用就抛出异常
ERROR io.netty.util.ResourceLeakDetector - LEAK: ByteBuf.release() was not called before it's garbage-collected.Recent access records: 1#1: io.netty.buffer.AdvancedLeakAwareByteBuf.toString(AdvancedLeakAwareByteBuf.java:697) io.netty.handler.codec.xml.XmlFrameDecoderTest.testDecodeWithXml(XmlFrameDecoderTest.java:157) io.netty.handler.codec.xml.XmlFrameDecoderTest.testDecodeWithTwoMessages(XmlFrameDecoderTest.java:133) ...Created at: io.netty.buffer.UnpooledByteBufAllocator.newDirectBuffer(UnpooledByteBufAllocator.java:55) io.netty.buffer.AbstractByteBufAllocator.directBuffer(AbstractByteBufAllocator.java:155) io.netty.buffer.UnpooledUnsafeDirectByteBuf.copy(UnpooledUnsafeDirectByteBuf.java:465) io.netty.buffer.WrappedByteBuf.copy(WrappedByteBuf.java:697) io.netty.buffer.AdvancedLeakAwareByteBuf.copy(AdvancedLeakAwareByteBuf.java:656) io.netty.handler.codec.xml.XmlFrameDecoder.extractFrame(XmlFrameDecoder.java:198) io.netty.handler.codec.xml.XmlFrameDecoder.decode(XmlFrameDecoder.java:174) io.netty.handler.codec.ByteToMessageDecoder.callDecode(ByteToMessageDecoder.java:227) io.netty.handler.codec.ByteToMessageDecoder.channelRead(ByteToMessageDecoder.java:140) io.netty.channel.ChannelHandlerInvokerUtil.invokeChannelReadNow(ChannelHandlerInvokerUtil.java:74) io.netty.channel.embedded.EmbeddedEventLoop.invokeChannelRead(EmbeddedEventLoop.java:142) io.netty.channel.DefaultChannelHandlerContext.fireChannelRead(DefaultChannelHandlerContext.java:317) io.netty.channel.DefaultChannelPipeline.fireChannelRead(DefaultChannelPipeline.java:846) io.netty.channel.embedded.EmbeddedChannel.writeInbound(EmbeddedChannel.java:176) io.netty.handler.codec.xml.XmlFrameDecoderTest.testDecodeWithXml(XmlFrameDecoderTest.java:147) io.netty.handler.codec.xml.XmlFrameDecoderTest.testDecodeWithTwoMessages(XmlFrameDecoderTest.java:133)从这里可以看出,是有泄露的。上面的堆栈信息只是贴了其中的一段。在完整的堆栈中可以看到自有的项目代码,包括具体的行数。标识的行数就是泄露的位置。
后面根据行数找到代码后,发现调用一个方法
DataBufferUtils.retain(dataBuffer)看到这行代码,再结合https://netty.io/wiki/reference-counted-objects.html这篇内容中的示例代码,瞬间就明白了
ByteBuf buf = ctx.alloc().directBuffer(); // 只要变量能获取到,就说明是可达的,即计数是大于0的assert buf.refCnt() == 1;
buf.retain(); // 如果在逻辑中retain一下,会将引用计数再一次加1,即使后面调用了释放,也只是从2变为1,而不是变为0。 // 那么垃圾回收永远都不会回收这个对象,也就造成了内存泄漏assert buf.refCnt() == 2;
boolean destroyed = buf.release();assert !destroyed;assert buf.refCnt() == 1;在程序中,只要使用到变量,就说明是已达的,不然你是不会使用到的。那么就说明其引用计数是大于0的。那么如果现在主动去retain()就会将引用计数再次增加1,即使后面调用release方法,也只是从2变为1,并不是0,所以不会被回收,也就是一直占用着。这也就解释了为什么内存会逐步上升直到资源消耗完。
资源不足时的其他表现
在排查问题的过程中,有很多其他的表现,在当时都立马解释了,下面做一个分享
网关的Prometheus监控为什么会存在断点
- 网关重启,重启需要时间,所以在重启的时间段内无数据,故会造成断点,呈现出来的数据就是不连续
- 网关资源枯竭,可能导致无法上报数据
在网关Error日志中,除了feign调用的异常外,还有其他异常,正常情况下应该是没有的
因为资源枯竭,会导致程序无法正常处理业务,故会出现类似的错误
在排查这些问题时,其实很容易被这些“周边”问题带偏。用通俗的话来讲,就是”病急乱投医”,没有找到真正的病因,就会盲目的去试,从而浪费了大量的时间和精力。
最后
技术问题排查和业务问题排查是两个不同的方向。业务问题排查只需要跟着代码一步一步走就OK,实在不行还可以和产品、测试沟通。总之,有很多途径能够获取信息来辅助判断。技术问题的排查,绝大部分是在学习和探索,对于知识面的广度有一定的要求,因为思维要足够的发散。同时,也需要对某一块的技术有一定的聚焦,这是解决问题的核心能力。所以现在可以理解为啥有很多专家了吧,例如Java专家、Redis专家等,因为他们可以在有限的时间内解决一些核心问题。我以前就不太理解为啥有技术专家,现在我理解了
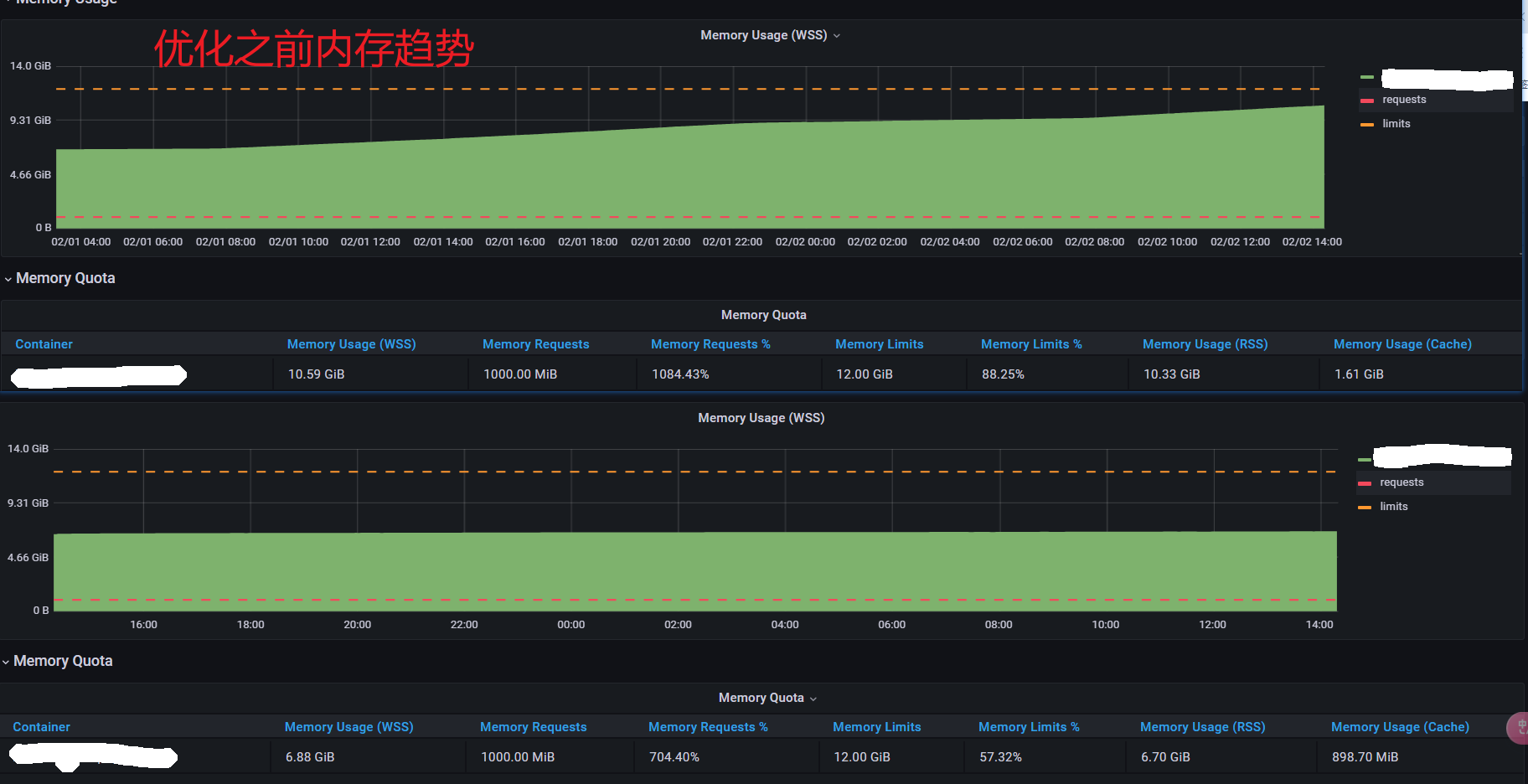
最最最后,贴一下优化的结果
网站当前构建日期: 2024.07.27