DDD在公司的实践记录
初步实践,有很多不足的地方,请多多指教
Domain Primitive
可以理解为DDD的基础数据类型。
Primitive定义: 不从任何其他事物发展而来;初级的形成或生长的早期阶段。例如OrderNo数据类型。
DP在DDD中是一切模型、方法、架构的基础
案例分析
反例:
User register(String name, String phone, String address)
User findByName(String name);User findByPhone(String phone);User findByNameAndPhone(String name, String phone);接口清晰度不够,在运行时其实是如下的内容:
User register(String, String, String); // 容易传错顺序
User findByName(String); // 只能靠方法名来知晓方法的意图User findByPhone(String);User findByNameAndPhone(String, String); // 容易传错顺序在编译时不会报错,只会在运行时可能会报错。如果用了DP就可以解决这个问题:
正例:
public User register(Name, PhoneNumber, Address)DRY原则: Don’t Repeat Yourself. 简单来讲,写代码的时候,如果出现雷同片段,就要想办法把他们提取出来,成为一段独立的代码。这样的抽象,可以保证任何调用这段代码的程序都能得到一致的结果;同时在需要修改时也能保证所有调用处都能获得更新。
如何识别和提取DP?
- 将隐性的概念显性化(Make Implicit Concepts Explicit). 显性化的对象称之为Value Object,即VO。一般来说 VO 都是 Immutable 的。VO里面的属性使用final修饰
VO其实是生成了一个 Type(数据类型)和一个 Class(类):
- Type 指我们在今后的代码里可以通过 PhoneNumber 去显性的标识电话号这个概念
- Class 指我们可以把所有跟电话号相关的逻辑完整的收集到一个文件里
- 将 隐性的 上下文 显性化(Make Implicit Context Explicit)
将相关的对象合并为一个VO。而这种相关的对象则称之为上下文
反例:
public void pay(BigDecimal money, Long recipientId) { BankService.transfer(money, "CNY", recipientId);}正例:
@Valuepublic class Money { private BigDecimal amount; private Currency currency; public Money(BigDecimal amount, Currency currency) { this.amount = amount; this.currency = currency; }}将默认货币这个隐性的上下文概念显性化,并且和金额合并为 Money
- 封装 多对象 行为 (Encapsulate Multi-Object Behavior)
反例:
public void pay(Money money, Currency targetCurrency, Long recipientId) { if (money.getCurrency().equals(targetCurrency)) { BankService.transfer(money, recipientId); } else { BigDecimal rate = ExchangeService.getRate(money.getCurrency(), targetCurrency); BigDecimal targetAmount = money.getAmount().multiply(new BigDecimal(rate)); Money targetMoney = new Money(targetAmount, targetCurrency); BankService.transfer(targetMoney, recipientId); }}这个case最大的问题在于,金额的计算被包含在了支付的服务中,涉及到的对象也有2个 Currency ,2 个 Money ,1 个 BigDecimal ,总共 5 个对象。这种涉及到多个对象的业务逻辑,需要用 DP 包装掉
正例:
@Valuepublic class ExchangeRate { private BigDecimal rate; private Currency from; private Currency to;
public ExchangeRate(BigDecimal rate, Currency from, Currency to) { this.rate = rate; this.from = from; this.to = to; }
public Money exchange(Money fromMoney) { notNull(fromMoney); isTrue(this.from.equals(fromMoney.getCurrency())); BigDecimal targetAmount = fromMoney.getAmount().multiply(rate); return new Money(targetAmount, to); }}ExchangeRate 汇率对象,通过封装金额计算逻辑以及各种校验逻辑,让原始代码
public void pay(Money money, Currency targetCurrency, Long recipientId) { ExchangeRate rate = ExchangeService.getRate(money.getCurrency(), targetCurrency); Money targetMoney = rate.exchange(money); BankService.transfer(targetMoney, recipientId);}DP、VO、DTO
Domain Primitive 是 Value Object 的进阶版,在原始 VO 的基础上要求每个 DP 拥有概念的整体,而不仅仅是值对象。在 VO 的 Immutable 基础上增加了 Validity 和行为。当然同样的要求无副作用(side-effect free)。
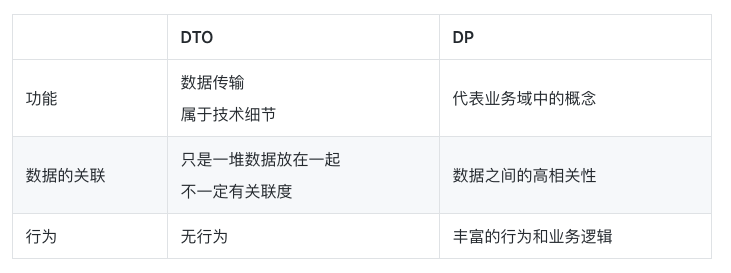
- Entity: 一个实体(Entity)是拥有ID的域对象,除了拥有数据之外,同时拥有行为。Entity和数据库储存格式无关,在设计中要以该领域的通用严谨语言(Ubiquitous Language)为依据。(这里可以理解聚合根)
例如,Account 是基于领域逻辑的实体类,它的字段和数据库储存不需要有必然的联系。Entity包含数据,同时也应该包含行为。在 Account 里,字段也不仅仅是String等基础类型,而应该尽可能用Domain Primitive代替,可以避免大量的校验代码
- Repository只负责Entity对象的存储和读取.
- Repository的修改方法出参和入参都应该是Entity.
- 对于查询,Repository的入参可以是DP,例如AccountId,AccountNumber,UserId等
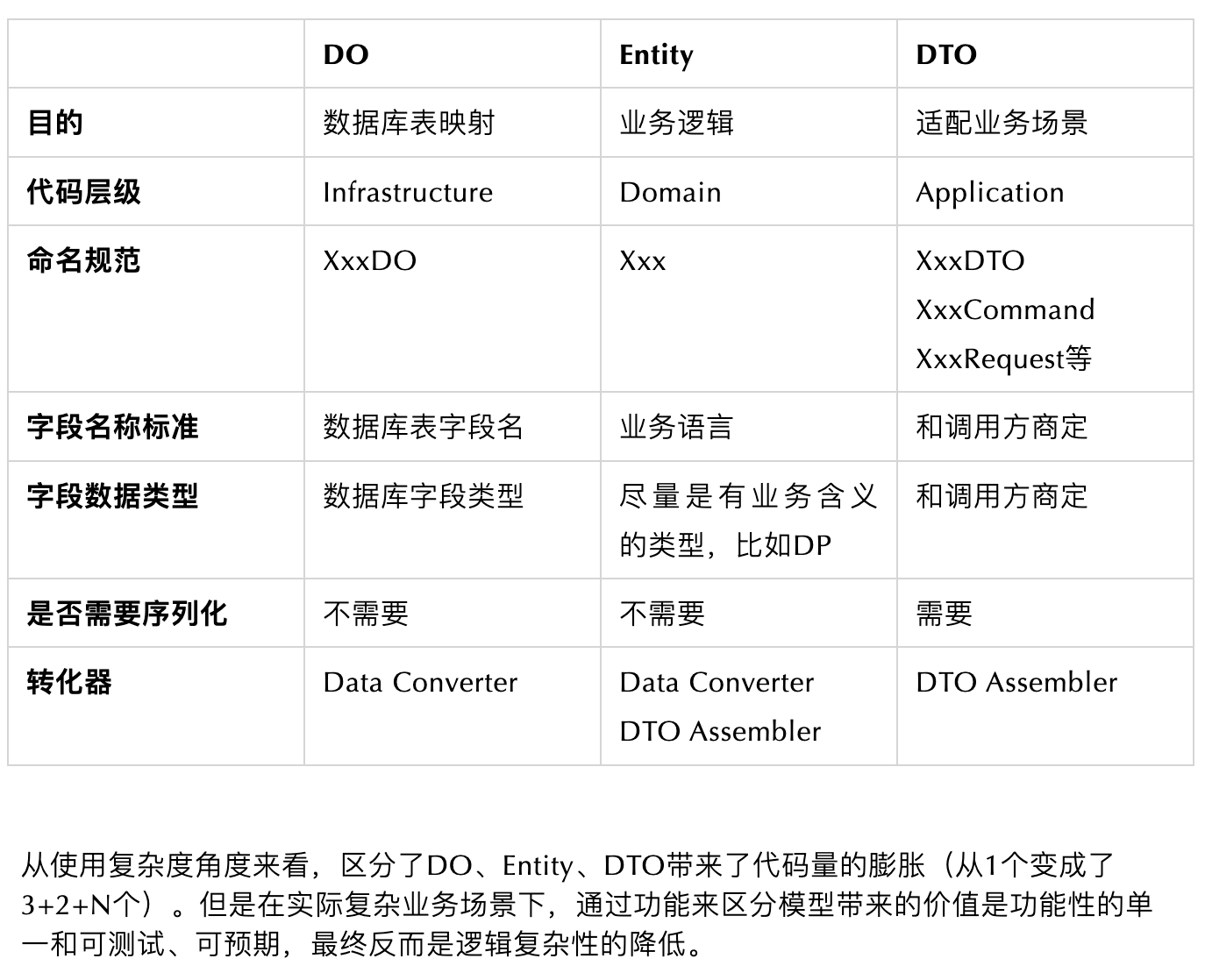
DAO对应的是一个特定的数据库类型的操作,相当于SQL的封装。所有操作的对象都是DO类,所有接口都可以根据数据库实现的不同而改变
Repository对应的是Entity对象读取储存的抽象,在接口层面做统一,不关注底层实现。 Repository的具体实现类通过调用DAO来实现各种操作,通过Builder/Factory对象实现AccountDO 到 Account之间的转化
- DO: 单纯的和数据库表的映射关系,每个字段对应数据库表的一个column,这种对象叫Data Object。DO只有数据,没有行为。
使用DP的场景
- 有格式限制的 String:比如Name,PhoneNumber,OrderNumber,ZipCode,Address等
- 有限制的Integer:比如OrderId(>0),Percentage(0-100%),Quantity(>=0)等
- 可枚举的 int :比如 Status(一般不用Enum因为反序列化问题)
- Double 或 BigDecimal:一般用到的 Double 或 BigDecimal 都是有业务含义的,比如 Temperature、Money、Amount、ExchangeRate、Rating 等
- 复杂的数据结构:比如 Map<String, List
> 等,尽量能把 Map 的所有操作包装掉,仅暴露必要行为
总结
Domain Primitive 是一个在特定领域里,拥有精准定义的、可自我验证的、拥有行为的 Value Object
- DP是一个传统意义上的Value Object,拥有Immutable的特性
- DP是一个完整的概念整体,拥有精准定义
- DP使用业务域中的原生语言
- DP可以是业务域的最小组成部分、也可以构建复杂组合
防腐层Anti-Corruption Layer
很多时候我们的系统会去依赖其他的系统,而被依赖的系统可能包含不合理的数据结构、API、协议或技术实现,如果对外部系统强依赖,会导致我们的系统被”腐蚀“。这个时候,通过在系统间加入一个防腐层,能够有效的隔离外部依赖和内部逻辑,无论外部如何变更,内部代码可以尽可能的保持不变。
因为现在的DB独立为原子服务了,将原子服务也纳入到防腐层
建立ACL的优点:
- 适配器:很多时候外部依赖的数据、接口和协议并不符合内部规范,通过适配器模式,可以将数据转化逻辑封装到ACL内部,降低对业务代码的侵入。
- 缓存:对于频繁调用且数据变更不频繁的外部依赖,通过在ACL里嵌入缓存逻辑,能够有效的降低对于外部依赖的请求压力。同时,很多时候缓存逻辑是写在业务代码里的,通过将缓存逻辑嵌入ACL,能够降低业务代码的复杂度。
- 兜底:如果外部依赖的稳定性较差,一个能够有效提升我们系统稳定性的策略是通过ACL起到兜底的作用,比如当外部依赖出问题后,返回最近一次成功的缓存或业务兜底数据。这种兜底逻辑一般都比较复杂,如果散落在核心业务代码中会很难维护,通过集中在ACL中,更加容易被测试和修改。
- 易于测试:类似于之前的Repository,ACL的接口类能够很容易的实现Mock或Stub,以便于单元测试。
- 功能开关:有些时候我们希望能在某些场景下开放或关闭某个接口的功能,或者让某个接口返回一个特定的值,我们可以在ACL配置功能开关来实现,而不会对真实业务代码造成影响。同时,使用功能开关也能让我们容易的实现Monkey测试,而不需要真正物理性的关闭外部依赖。
ACL防腐层的简单原理
- 对于依赖的外部对象,我们抽取出所需要的字段,生成一个内部所需的VO或DTO类
- 构建一个新的Facade,在Facade中封装调用链路,将外部类转化为内部类
- 针对外部系统调用,同样的用Facade方法封装外部调用链路
在一些理论框架里ACL Facade也被叫做Gateway,含义是一样的
Repository和Entity
- 通过Account对象,避免了其他业务逻辑代码和数据库的直接耦合,避免了当数据库字段变化时,大量业务逻辑也跟着变的问题。
- 通过Repository,改变业务代码的思维方式,让业务逻辑不再面向数据库编程,而是面向领域模型编程。
- Account属于一个完整的内存中对象,可以比较容易的做完整的测试覆盖,包含其行为。
- Repository作为一个接口类,可以比较容易的实现Mock或Stub,可以很容易测试。
- AccountRepositoryImpl实现类,由于其职责被单一出来,只需要关注Account到AccountDO的映射关系和Repository方法到DAO方法之间的映射关系,相对于来说更容易测试。
通过Entity、Domain Primitive和Domain Service封装所有的业务逻辑
有很多业务逻辑是跟外部依赖的代码混合的,包括金额计算、账户余额的校验、转账限制、金额增减等。这种逻辑混淆导致了核心计算逻辑无法被有效的测试和复用。
Domain Service出现的场景可以参考以下描述:
sourceAccount.deposit(sourceMoney); //转入targetAccount.withdraw(targetMoney); //转出这两个账号的转出和转入实际上是一体的,也就是说这种行为应该被封装到一个对象中去。特别是考虑到未来这个逻辑可能会产生变化:比如增加一个扣手续费的逻辑。这个时候在原有的TransferService中做并不合适,在任何一个Entity或者Domain Primitive里也不合适,需要有一个新的类去包含跨域对象的行为。这种对象叫做Domain Service。
总结: 就是将一个统一的行为,且这个行为影响同一个实体的多个示例的的,应当提取为一个DomainService
六边型架构
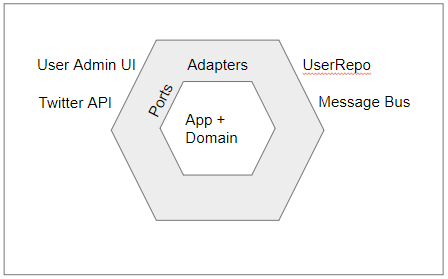
我们会发现每一个对外部的抽象类其实就是输入或输出,类似于计算机系统中的I/O节点。这个观点在CQRS架构中也同样适用,将所有接口分为Command(输入)和Query(输出)两种。
在这张图中:
- I/O的具体实现在模型的最外层
- 每个I/O的适配器在灰色地带
- 每个Hex的边是一个端口
- Hex的中央是应用的核心领域模型
在Hex中,架构的组织关系第一次变成了一个二维的内外关系,而不是传统一维的上下关系。同时在Hex架构中我们第一次发现UI层、DB层、和各种中间件层实际上是没有本质上区别的,都只是数据的输入和输出,而不是在传统架构中的最上层和最下层。
DDD代码的演进/变化速度
在传统架构中,代码从上到下的变化速度基本上是一致的,改个需求需要从接口、到业务逻辑、到数据库全量变更,而第三方变更可能会导致整个代码的重写。但是在DDD中不同模块的代码的演进速度是不一样的:
-
Domain层属于核心业务逻辑,属于经常被修改的地方。比如:原来不需要扣手续费,现在需要了之类的。通过Entity能够解决基于单个对象的逻辑变更,通过Domain Service解决多个对象间的业务逻辑变更。
-
Application层属于Use Case(业务用例)。业务用例一般都是描述比较大方向的需求,接口相对稳定,特别是对外的接口一般不会频繁变更。添加业务用例可以通过新增Application Service或者新增接口实现功能的扩展。
-
Infrastructure层属于最低频变更的。一般这个层的模块只有在外部依赖变更了之后才会跟着升级,而外部依赖的变更频率一般远低于业务逻辑的变更频率。
所以在DDD架构中,能明显看出越外层的代码越稳定,越内层的代码演进越快,真正体现了 领域“驱动” 的核心思想。
贫血模型
很多Java开发对Entity的理解停留在了数据映射层面,忽略了Entity实体的本身行为,造成今天很多的模型仅包含了实体的数据和属性,而所有的业务逻辑都被分散在多个服务、Controller、Utils工具类中,这个就是Martin Fowler所说的的Anemic Domain Model(贫血领域模型)。
贫血模型的缺陷:
- 无法保护模型对象的完整性和一致性:因为对象的所有属性都是公开的,只能由调用方来维护模型的一致性,而这个是没有保障的;
- 对象操作的可发现性极差:单纯从对象的属性上很难看出来都有哪些业务逻辑,什么时候可以被调用,以及可以赋值的边界是什么;
- 代码逻辑重复:比如校验逻辑、计算逻辑,都很容易出现在多个服务、多个代码块里,提升维护成本和bug出现的概率;一类常见的bug就是当贫血模型变更后,校验逻辑由于出现在多个地方,没有能跟着变,导致校验失败或失效。
- 代码的健壮性差:比如一个数据模型的变化可能导致从上到下的所有代码的变更
- 强依赖底层实现:业务代码里强依赖了底层数据库、网络/中间件协议、第三方服务等,造成核心逻辑代码的僵化且维护成本高。
贫血模型泛滥的原因:
- 数据库思维:从有了数据库的那一天起,开发人员的思考方式就逐渐从“写业务逻辑“转变为了”写数据库逻辑”,也就是我们经常说的在写CRUD代码。
- 贫血模型“简单”:贫血模型的优势在于“简单”,仅仅是对数据库表的字段映射,所以可以从前到后用统一格式串通。这里简单打了引号,是因为它只是表面上的简单,实际上当未来有模型变更时,你会发现其实并不简单,每次变更都是非常复杂的事情
- 脚本思维:很多常见的代码都属于“脚本”或“胶水代码”,也就是流程式代码。脚本代码的好处就是比较容易理解,但长久来看缺乏健壮性,维护成本会越来越高。
要正确认识数据模型和领域模型:
- 数据模型(Data Model):指业务数据该如何持久化,以及数据之间的关系,也就是传统的ER模型;
- 业务模型/领域模型(Domain Model):指业务逻辑中,相关联的数据该如何联动。
解决贫血模型根本方案
就是要在代码里严格区分Data Model和Domain Model。在真实代码结构中,Data Model和 Domain Model实际上会分别在不同的层里,Data Model只存在于数据层,而Domain Model在领域层,而链接了这两层的关键对象,就是Repository。—— 这也是Repository的价值
Change-Tracking 变更追踪
- 基于Snapshot的方案:当数据从DB里取出来后,在内存中保存一份snapshot,然后在数据写入时和snapshot比较。常见的实现如Hibernate
- 基于Proxy的方案:当数据从DB里取出来后,通过weaving的方式将所有setter都增加一个切面来判断setter是否被调用以及值是否变更,如果变更则标记为Dirty。在保存时根据Dirty判断是否需要更新。常见的实现如Entity Framework
在真实业务中使用DDD的特殊性
在真实的业务逻辑里,我们的领域模型或多或少的都有一定的“特殊性”,如果100%的要符合DDD规范可能会比较累,所以最主要的是梳理一个对象行为的影响面,然后作出设计决策,即:
- 是仅影响单一对象还是多个对象,
- 规则未来的拓展性、灵活性,
- 性能要求,
- 副作用的处理,等等
当然,很多时候一个好的设计是多种因素的取舍,需要大家有一定的积累,真正理解每个架构背后的逻辑和优缺点。一个好的架构师不是有一个正确答案,而是能从多个方案中选出一个最平衡的方案。
使用DDD后的开发方式
我们可能先写Domain层的业务逻辑,然后再写Application层的组件编排,最后才写每个外部依赖的具体实现。这种架构思路和代码组织结构就叫做Domain-Driven Design(领域驱动设计,或DDD)。所以DDD不是一个特殊的架构设计,而是所有Transction Script代码经过合理重构后一定会抵达的终点
Orchestration vs Choreography
Orchestration:通常出现在脑海里的是一个交响乐团(Orchestra,注意这两个词的相似性),如下图。交响乐团的核心是一个唯一的指挥家Conductor,在一个交响乐中,所有的音乐家必须听从Conductor的指挥做操作,不可以独自发挥。所以在Orchestration模式中,所有的流程都是由一个节点或服务触发的。我们常见的业务流程代码,包括调用外部服务,就是Orchestration,由我们的服务统一触发。
Choreography:通常会出现在脑海的场景是一个舞剧(来自于希腊文的舞蹈,Choros),如下图。其中每个不同的舞蹈家都在做自己的事,但是没有一个中心化的指挥。通过协作配合,每个人做好自己的事,整个舞蹈可以展现出一个完整的、和谐的画面。所以在Choreography模式中,每个服务都是独立的个体,可能会响应外部的一些事件,但整个系统是一个整体。
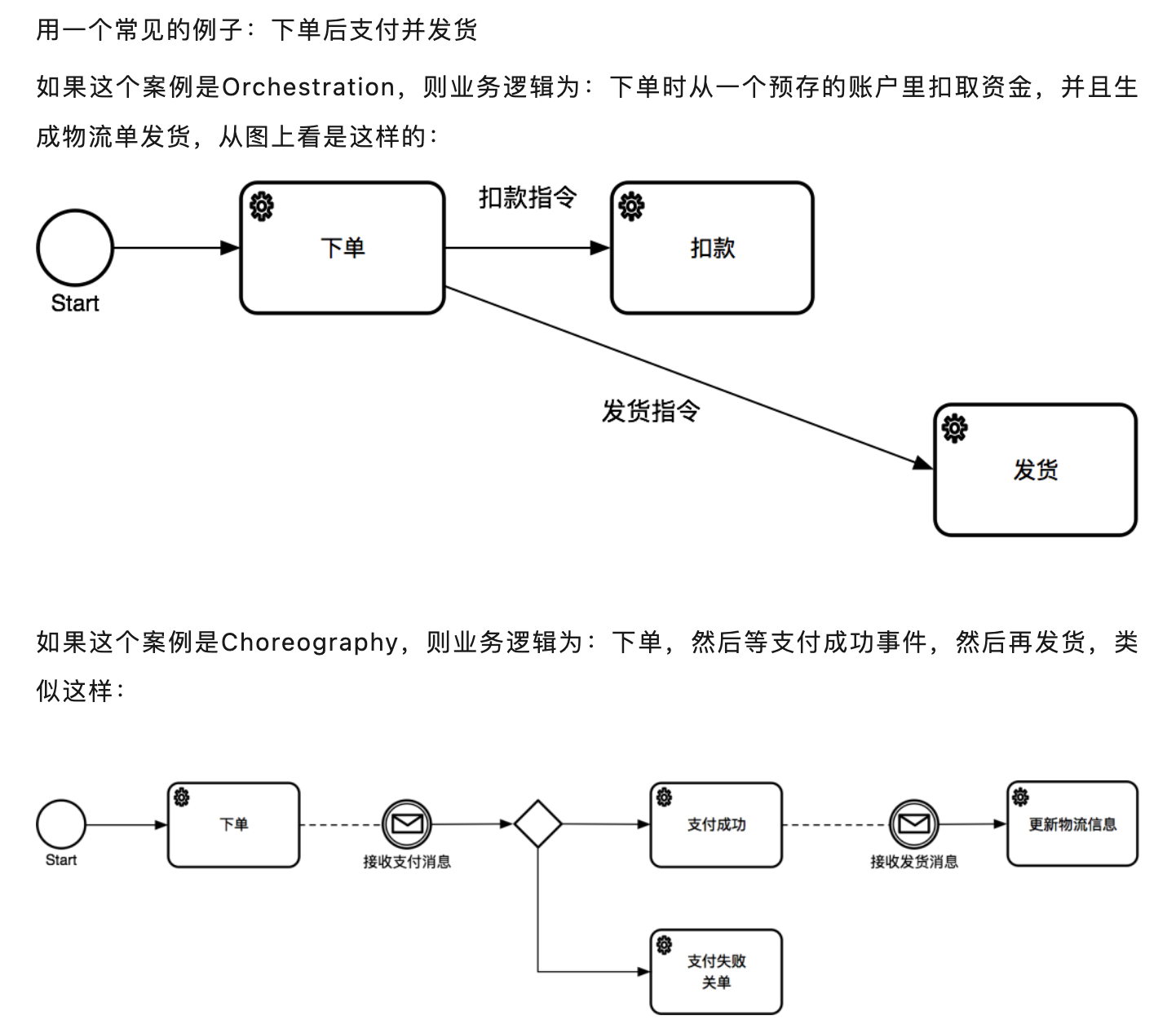
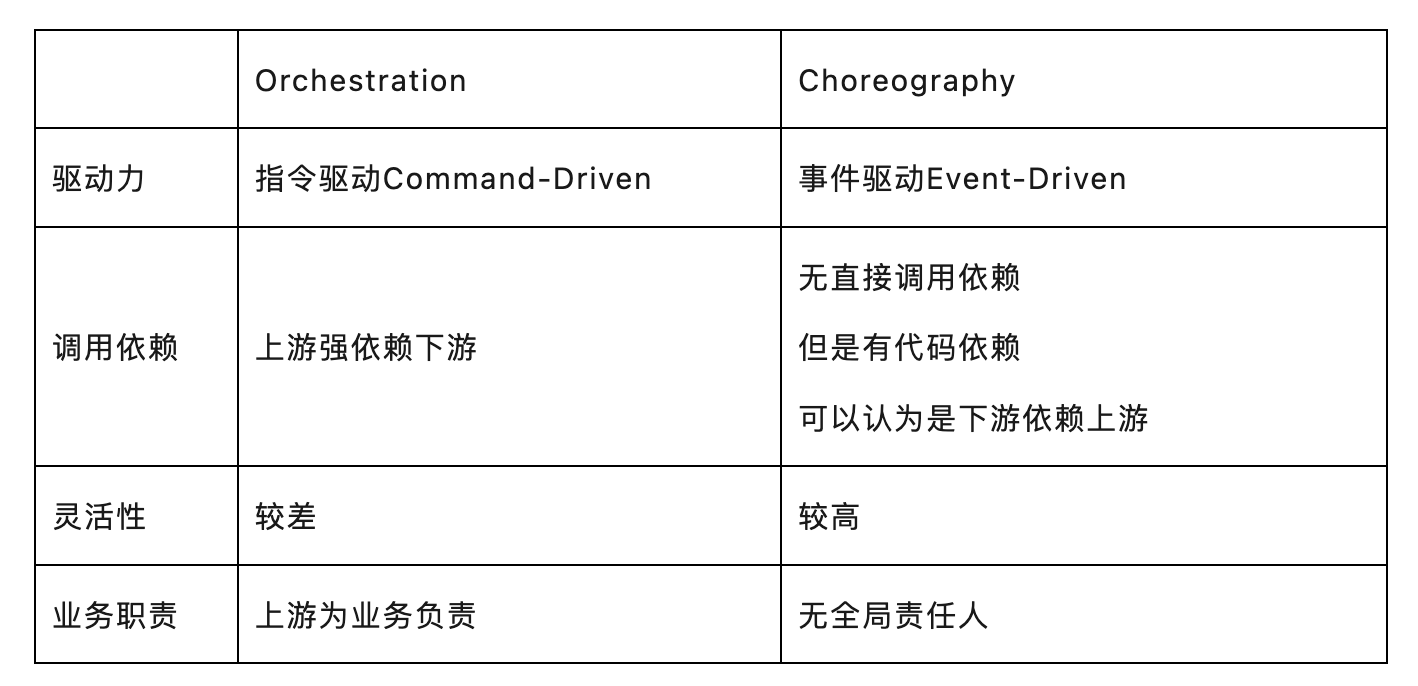
业务流程设计模式:
- 没有最好的模式,取决于业务场景、依赖关系、以及是否有业务“负责人”。避免拿着锤子找钉子。
参考内容:
- https://mp.weixin.qq.com/s/kpXklmidsidZEiHNw57QAQ
- https://mp.weixin.qq.com/s/MU1rqpQ1aA1p7OtXqVVwxQ 详细的示例 + 架构说明 + 包结构说明
- https://mp.weixin.qq.com/s/1bcymUcjCkOdvVygunShmw
- https://mp.weixin.qq.com/s/w1zqhWGuDPsCayiOgfxk6w
- https://mp.weixin.qq.com/s?__biz=MzAxNDEwNjk5OQ==&mid=2650427571&idx=1&sn=bfc3c1c6f189965a1a4c7f3918012405&scene=19 完整的案例 这里提到最多的就是单一职责
网站当前构建日期: 2024.10.21