分布式锁
分布式场景下解决并发问题,需要应用分布式锁技术。分布式锁的目的是保证在分布式部署的应用集群中,多个服务在请求同一个资源时,只能被一台机器上的一个线程操作,避免出现并发问题。
分布式锁的常用实现
Section titled “分布式锁的常用实现”实现分布式锁目前有三种流行方案,即基于数据库、Redis和ZooKeeper
1. 基于数据库
Section titled “1. 基于数据库”基于关系型数据库实现分布式锁,是依赖数据库的唯一性来实现资源锁定,比如主键和唯一索引等。
具体实现: 创建一个独立的锁表,将锁表中的一个字段设置成唯一,然后多个请求尝试插入数据,如果插入成功则表明获取到锁。其他请求自然会因为唯一性而插入失败,即获取锁失败。
获取到锁的线程执行完之后,删除刚刚插入的记录,即释放锁。
1.1 基于数据库实现分布式锁的缺陷
Section titled “1.1 基于数据库实现分布式锁的缺陷”存在单点故障风险
Section titled “存在单点故障风险”数据库实现方式强依赖数据库的可用性,一旦数据库挂掉,则会导致业务系统不可用,为了解决这个问题,需要配置数据库主从机器,防止单点故障。
超时无法失效
Section titled “超时无法失效”如果一旦解锁操作失败,则会导致锁记录一直在数据库中,其他线程无法再获得锁,解决这个问题,可以添加独立的定时任务,通过时间戳对比等方式,删除超时数据。
可重入性是锁的一个重要特性,以 Java 语言为例,常见的 Synchronize、Lock 等都支持可重入。在数据库实现方式中,同一个线程在没有释放锁之前无法再次获得该锁,因为数据已经存在,再次插入会失败。实现可重入,需要改造加锁方法,额外存储和判断线程信息,不阻塞获得锁的线程再次请求加锁。
无法实现阻塞
Section titled “无法实现阻塞”其他线程在请求对应方法时,插入数据失败会直接返回,不会阻塞线程,如果需要阻塞其他线程,需要不断的重试 insert 操作,直到数据插入成功,这个操作是服务器和数据库资源的极大浪费。
2. 基于 ZooKeeper 实现
Section titled “2. 基于 ZooKeeper 实现”ZooKeeper有四种节点类型,包括持久节点、持久顺序节点、临时节点和临时顺序节点。
临时: 会自动失效,可以避免某些情况下锁无法删除而产生死锁的问题
主要是使用节点唯一性来实现(实际业务上如果创建失败,就丢到队列中去排队)
释放锁就是删除节点,删除后然后通知其他人过来创建节点,即加锁
如果机器宕机了,没有删除掉,资源就会一直被占着,怎么处理呢?
创建临时节点就好,客户端断开,节点就自动删除了
在实际开发中,可以应用 Apache Curator 来快速实现分布式锁,Curator 是 Netflix 公司开源的一个 ZooKeeper 客户端,对 ZooKeeper 原生 API 做了抽象和封装
使用zk可能会造成的问题
Section titled “使用zk可能会造成的问题”羊群效应,导致占用服务器资源
监听,是所有服务都去监听一个节点的,节点的释放也会通知所有的服务器,如果是900个服务器呢? 这对服务器是很大的一个挑战,一个释放的消息,就好像一个牧羊犬进入了羊群,大家都四散而开,随时可能干掉机器,会占用服务资源,网络带宽等等。 这就是羊群效应。
羊群效应处理方法:
临时顺序节点,只监听前一个节点,以此类推,只关注自己前后,就不会出现羊群效应
使用zk实现分布式锁的缺点
Section titled “使用zk实现分布式锁的缺点”- 性能没有缓存服务高。因为每次在创建锁和释放锁的过程中,都要动态创建、销毁瞬时节点来实现锁功能。ZK中创建和删除节点只能通过Leader服务器来执行,然后将数据同步到所有的Follower机器上。
- 可能带来并发问题。由于网络抖动,客户端ZK集群的session连接断了,那么zk以为客户端挂了,就会删除临时节点,这时候其他客户端就可以获取到分布式锁了。就可能产生并发问题了。
3. 基于Redis(重点)
Section titled “3. 基于Redis(重点)”相比基于数据库实现分布式锁,缓存的性能更好,并且各种缓存组件也提供了多种集群方案,可以解决单点问题。
具体实现: 添加了 SETEX 命令,SETEX 支持 setnx 和 expire 指令组合的原子操作。
以上只是简单的实现,实际实现需要考虑更多的点,下面的板块就详细的介绍下
分布式锁的常用实现之Redis
Section titled “分布式锁的常用实现之Redis”1. 一个完备的分布式锁,需要支持以下特性
Section titled “1. 一个完备的分布式锁,需要支持以下特性”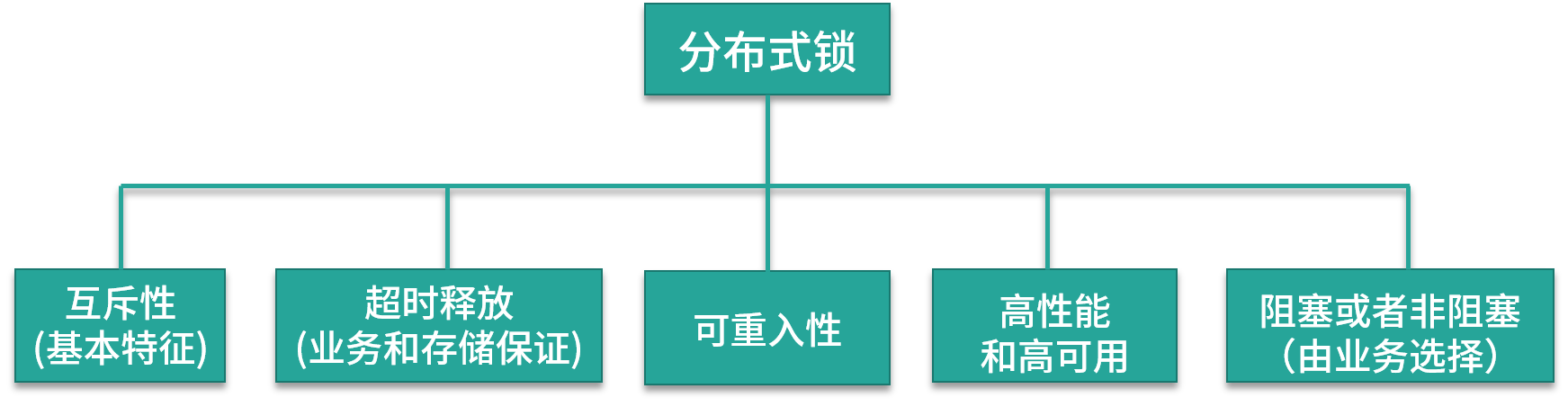
该图片来自互联网
- 互斥性,互斥是锁的基本特征,同一时刻只能有一个线程持有锁,执行临界操作;
- 超时释放,超时释放是锁的另一个必备特性,可以对比 MySQL InnoDB 引擎中的 innodb_lock_wait_timeout 配置,通过超时释放,防止不必要的线程等待和资源浪费;
- 可重入性,在分布式环境下,同一个节点上的同一个线程如果获取了锁之后,再次请求还是可以成功;
- 高性能和高可用,加锁和解锁的开销要尽可能的小,同时也需要保证高可用,防止分布式锁失效;
- 支持阻塞和非阻塞性,对比 Java 语言中的 wait() 和 notify() 等操作,这个一般是在业务代码中实现,比如在获取锁时通过 while(true) 或者轮询来实现阻塞操作。
实现一个相对完备的分布式锁,并不是锁住资源就可以了,还需要满足一些额外的特性,否则会在业务开发中出现各种各样的问题。
- 使用 setnx 实现分布式锁 ——— 不支持超时释放
- 使用 setnx 和 expire 实现分布式锁 ——— setnx 和 expire 这两条命令不具备原子性。如果一个线程在执行完 setnx 之后突然崩溃,导致锁没有设置过期时间,那么这个锁就会一直存在,无法被其他线程获取。
- 使用 setex 实现分布式锁。
SET key value expireTime nx同时解决了原子性和超时的问题 ——— 但在实际业务中,如果对超时时间设置不合理,存在这样一种可能:在加锁和释放锁之间的业务逻辑执行的太长,以至于超出了锁的超时限制,缓存将对应 key 删除,其他线程可以获取锁,出现对加锁资源的并发操作。
对于第三种实现方案中的问题如何解决呢? 可以使用Redisson中的Watch Dog,给锁续期。Redisson提供的分布式锁是支持锁自动续期的,也就是说,如果线程仍旧没有执行完,那么redisson会自动给redis中的目标key延长超时时间,这在Redisson中称之为 Watch Dog 机制。
Config config = new Config();config.useClusterServers().addNodeAddress("redis://xx.xx.xx.xx:xxxx1").addNodeAddress("redis://xx.xx.xx.xx:xxxx2")// 等等;
RedissonClient redisson = Redisson.create(config);
RLock lock = redisson.getLock("anyLock");
lock.lock();
lock.unlock();只需要通过它的 API 中的 Lock 和 Unlock 即可完成分布式锁,可以看到非常简单,而且考虑了很多细节:
- Redisson 所有指令都通过 Lua 脚本执行,Redis 支持 Lua 脚本原子性执行。
- Redisson 设置一个 Key 的默认过期时间为 30s,但是如果获取锁之后,会有一个WatchDog每隔10s将key的超时时间设置为30s。
基于Starlight构建 | 主题色: Flexoki | 构建日期: 2026.05.22 | Change Log | Ko-fi