Spring Cloud Gateway Reactive
之前网关在遭遇流量洪峰时会重启
经过AI分析得出原因是因为网关的过滤器逻辑中使用了同步逻辑导致。因为Spring Cloud Gateway 底层是基于 Netty 和 Reactor 异步非阻塞模型 构建的,如果在过滤器中使用了同步调用,会阻塞 Reactor 的工作线程(通常称为 Event Loop 线程)。一旦Reactor的工作线程被阻塞会导致以下问题:
- 整个事件循环被挂起,不能继续处理其他请求
- 吞吐量下降,响应变慢,网关处理能力大幅降低
- JVM 的 GC 压力加大。系统负载升高
因为不能处理其他请求,k8s的健康检查探针探测到服务异常,就会杀死网关服务。
阻塞代码分析方法
Section titled “阻塞代码分析方法”借助开源项目 BlockHound 来检查阻塞代码。 BlockHound文档
使用BlockHound检测出了项目中主要是同步Redis阻塞了工作线程
- 主要: 同步代码修改为响应式,使用ReactiveRedis来替代同步Redis
- 次要: 移除无效代码,减少无效的网络请求
- 代码整理。移除无效代码,减少过滤器中的无效逻辑调用。例如: 从请求中解析相关用户信息,最后却什么也不做、请求耗时统计等
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis-reactive</artifactId></dependency>因为需要压测网关本身优化效果,需要消除下游服务对网关的测试结果的影响,所以让请求在网关内部闭环,不涉及其他服务。
package com.moatkon;
import java.nio.charset.StandardCharsets;import org.springframework.cloud.gateway.filter.GatewayFilterChain;import org.springframework.cloud.gateway.filter.GlobalFilter;import org.springframework.core.Ordered;import org.springframework.http.HttpStatus;import org.springframework.stereotype.Component;import org.springframework.web.server.ServerWebExchange;import reactor.core.publisher.Mono;
@Componentpublic class MoatkonEndpointFilter implements GlobalFilter, Ordered {
@Override public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) { String path = exchange.getRequest().getURI().getPath(); if ("/dummy".equals(path)) { byte[] data = "OK".getBytes(StandardCharsets.UTF_8); exchange.getResponse().setStatusCode(HttpStatus.OK); exchange.getResponse().getHeaders().setContentLength(data.length); return exchange.getResponse().writeWith(Mono.just(exchange.getResponse() .bufferFactory().wrap(data))); }
return chain.filter(exchange); }
@Override public int getOrder() { return -1; // 保证早期执行 }}package com.moatkon;
import org.springframework.cloud.gateway.route.RouteLocator;import org.springframework.cloud.gateway.route.builder.RouteLocatorBuilder;import org.springframework.context.annotation.Bean;import org.springframework.stereotype.Component;
@Componentpublic class MoatkonRouteLocator {
@Bean public RouteLocator customRouteLocator(RouteLocatorBuilder builder) { return builder.routes() .route("dummy_test", r -> r .path("/dummy") .filters(f -> f .addResponseHeader("X-Test", "gateway") ) .uri("no://backend")) // 注意:使用一个不会被解析的uri .build(); }
}- 测试环境 、 2个网关节点
- 压测时间选择在晚上,测试环境流量少。(公司没有压测环境…有压测环境就不用这么麻烦了)
为了方便测试不同并发下的网关表现,写了一个脚本,方便数据收集与处理。
- 压测工具使用ab
- 固定请求总数
echo '{"hello":"Hello World"}' > post_data.json#!/bin/bash
# 响应式优势测试策略 - 带错误处理版本# 目标:找到响应式Redis相比同步Redis的性能拐点
TOKEN="Authorization: 自定义token"POST_DATA="post_data.json"# 固定总请求数,测试不同并发级别的性能TOTAL_REQUESTS=8000
## 压测URL="http://moatkon-gateway-test.com/dummy"GATEWAY_HOST="moatkon-gateway-test"GATEWAY_PORT="80"# 同步redisRESULT_FILE="k8s_reactive_performance_test_sync.log"# 响应式redis# RESULT_FILE="k8s_reactive_performance_test_reactive.log"
echo "响应式Redis性能测试开始..." | tee $RESULT_FILEecho "测试时间: $(date)" | tee -a $RESULT_FILEecho "========================================" | tee -a $RESULT_FILE
# 测试函数 - 增强错误处理run_test() { concurrency=$1 requests=$2 test_name=$3
echo "[$test_name] 并发: $concurrency, 请求: $requests" | tee -a $RESULT_FILE
# 运行压测 echo "🚀 开始压测..." | tee -a $RESULT_FILE result=$(ab -n $requests -c $concurrency -T "application/json" -H "$TOKEN" -p $POST_DATA $URL 2>&1) ab_exit_code=$?
# 检查ab命令执行结果 if [ $ab_exit_code -ne 0 ]; then echo "❌ 压测执行失败 (退出码: $ab_exit_code)" | tee -a $RESULT_FILE echo "错误信息:" | tee -a $RESULT_FILE echo "$result" | grep -E "(apr_socket_recv|Connection refused|Connection timed out|failed|error)" | tee -a $RESULT_FILE return 1 fi
# 提取关键指标 qps=$(echo "$result" | grep "Requests per second" | awk '{print $4}') avg_time=$(echo "$result" | grep "Time per request" | head -1 | awk '{print $4}') failed=$(echo "$result" | grep "Failed requests" | awk '{print $3}') p95_time=$(echo "$result" | grep "95%" | awk '{print $2}') connect_errors=$(echo "$result" | grep "Connect:" | awk '{print $2}')
# 检查是否有严重错误 if [ ! -z "$connect_errors" ] && [ "$connect_errors" -gt 0 ]; then echo "⚠️ 连接错误: $connect_errors 个" | tee -a $RESULT_FILE fi
if [ ! -z "$failed" ] && [ "$failed" -gt 0 ]; then failure_rate=$(echo "scale=2; $failed * 100 / $requests" | bc 2>/dev/null || echo "N/A") echo "⚠️ 失败请求: $failed (${failure_rate}%)" | tee -a $RESULT_FILE fi
# 记录结果 if [ ! -z "$qps" ] && [ ! -z "$avg_time" ]; then echo " ✅ QPS: $qps" | tee -a $RESULT_FILE echo " ✅ 平均响应时间: ${avg_time}ms" | tee -a $RESULT_FILE echo " 📊 95%响应时间: ${p95_time}ms" | tee -a $RESULT_FILE echo " 📊 失败请求: $failed" | tee -a $RESULT_FILE else echo "❌ 无法解析测试结果" | tee -a $RESULT_FILE echo "完整输出:" | tee -a $RESULT_FILE echo "$result" | tee -a $RESULT_FILE return 1 fi
echo " ---" | tee -a $RESULT_FILE return 0}
# 阶段1:低并发基准测试echo "📊 阶段1:低并发基准测试 (总请求数: $TOTAL_REQUESTS)" | tee -a $RESULT_FILErun_test 10 $TOTAL_REQUESTS "低并发基准" || echo "⚠️ 低并发测试失败"sleep 3run_test 20 $TOTAL_REQUESTS "低并发基准" || echo "⚠️ 低并发测试失败"sleep 3run_test 50 $TOTAL_REQUESTS "低并发基准" || echo "⚠️ 低并发测试失败"sleep 5
# 阶段2:中等并发测试(响应式开始显现优势)echo "📊 阶段2:中等并发测试 (总请求数: $TOTAL_REQUESTS)" | tee -a $RESULT_FILE# run_test 100 $TOTAL_REQUESTS "中等并发" || echo "⚠️ 中等并发测试失败"# sleep 5run_test 200 $TOTAL_REQUESTS "中等并发" || echo "⚠️ 中等并发测试失败"sleep 5run_test 300 $TOTAL_REQUESTS "中等并发" || echo "⚠️ 中等并发测试失败"sleep 8
# 阶段3:高并发测试(响应式优势明显)echo "📊 阶段3:高并发测试 (总请求数: $TOTAL_REQUESTS)" | tee -a $RESULT_FILErun_test 500 $TOTAL_REQUESTS "高并发" || echo "⚠️ 高并发测试失败,可能接近服务极限"sleep 10run_test 800 $TOTAL_REQUESTS "高并发" || echo "⚠️ 高并发测试失败,可能接近服务极限"sleep 10run_test 1000 $TOTAL_REQUESTS "高并发" || echo "⚠️ 高并发测试失败,可能接近服务极限"sleep 10
# 阶段4:极高并发测试(找到性能瓶颈)echo "📊 阶段4:极高并发测试 (总请求数: $TOTAL_REQUESTS)" | tee -a $RESULT_FILEecho "⚠️ 开始极限测试,请监控服务状态..." | tee -a $RESULT_FILErun_test 2000 $TOTAL_REQUESTS "极高并发" || echo "❌ 极高并发测试失败,已达到服务极限"sleep 15run_test 3000 $TOTAL_REQUESTS "极高并发" || echo "❌ 极高并发测试失败,已达到服务极限"sleep 15run_test 4000 $TOTAL_REQUESTS "极高并发" || echo "❌ 极高并发测试失败,已达到服务极限"
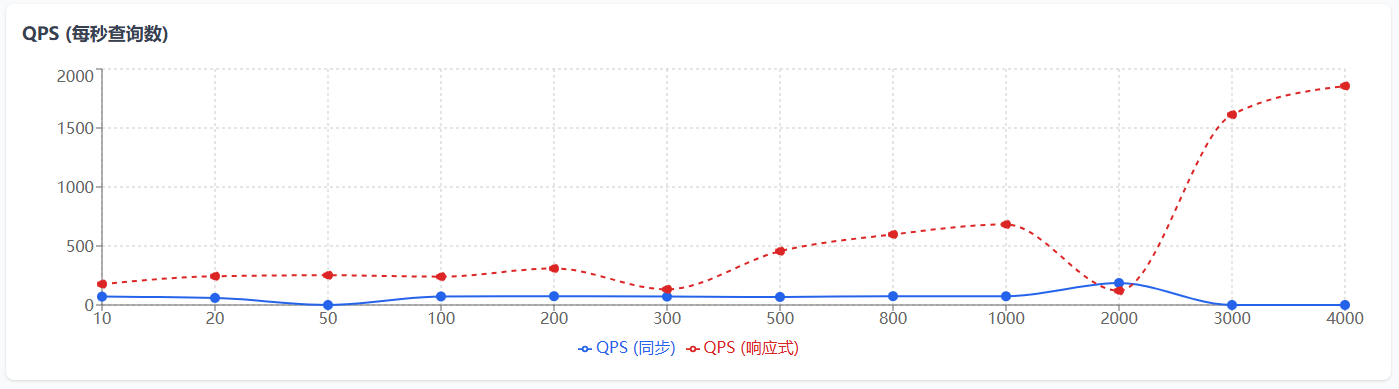
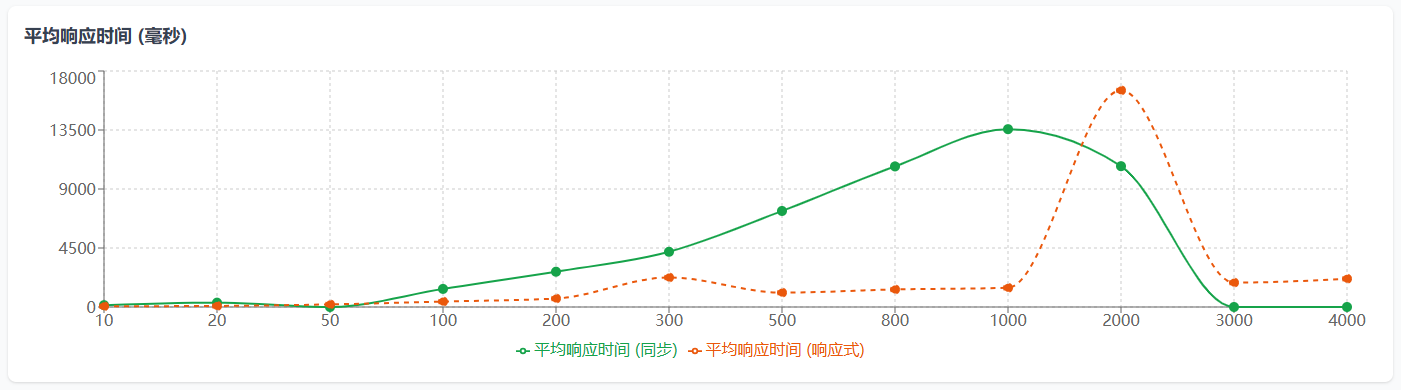
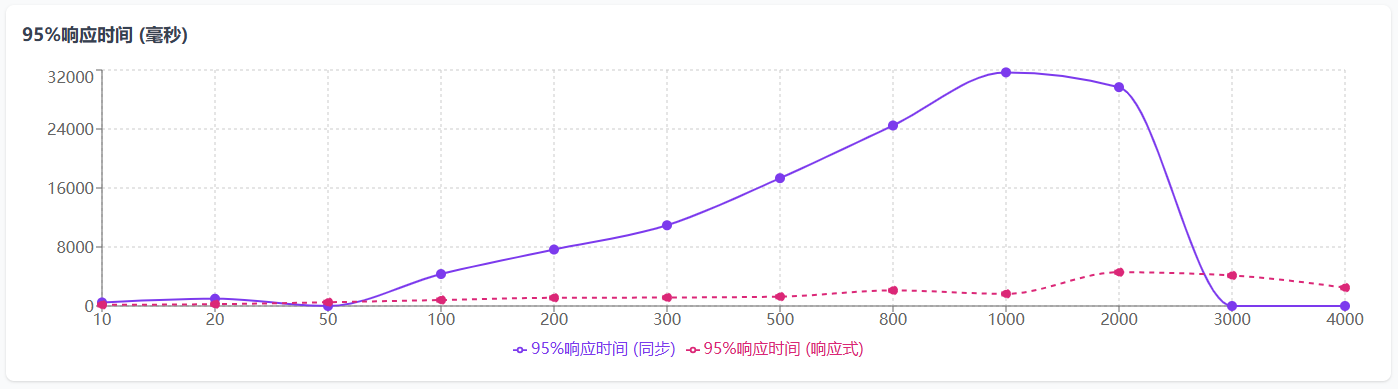
echo "测试完成!详细结果请查看: $RESULT_FILE" | tee -a $RESULT_FILEecho "测试结束时间: $(date)" | tee -a $RESULT_FILE| 并发数 | QPS(同步) | 平均响应时间(同步) | 95%响应时间(同步) | QPS(响应式) | 平均响应时间(响应式) | 95%响应时间(响应式) |
|---|---|---|---|---|---|---|
| 10 | 71.2 | 140.445 | 485 | 176.93 | 56.519 | 157 |
| 20 | 60.18 | 332.329 | 986 | 243.52 | 82.128 | 246 |
| 50 | 失败 | 失败 | 失败 | 252.08 | 198.353 | 508 |
| 100 | 72.43 | 1380.56 | 4332 | 240.29 | 416.168 | 814 |
| 200 | 74.3 | 2691.857 | 7655 | 309.46 | 646.285 | 1112 |
| 300 | 71.21 | 4212.883 | 10943 | 133.24 | 2251.537 | 1149 |
| 500 | 68.26 | 7324.498 | 17332 | 455.8 | 1096.98 | 1268 |
| 800 | 74.61 | 10722.655 | 24476 | 598.16 | 1337.427 | 2115 |
| 1000 | 73.73 | 13563.109 | 31676 | 682.45 | 1465.309 | 1649 |
| 2000 | 186.24 | 10739.042 | 29671 | 121.05 | 16522.11 | 4578 |
| 3000 | 失败(服务宕机) | 失败(服务宕机) | 失败(服务宕机) | 1612.74 | 1860.185 | 4137 |
| 4000 | 失败(服务宕机) | 失败(服务宕机) | 失败(服务宕机) | 1855.99 | 2155.183 | 2489 |
- 阻塞式代码在3000,4000并发都失败时网关服务重启了,和之前线上表现一致。
- 如果要体现响应式Redis的优势必须上大并发,如果并发过低,同步和异步的差异不明显甚至会出现异步性能低于同步的情况(这个是我遇到的实际情况,花了点时间查了资料)
图表说明:
- X轴表示并发数
- 实线表示同步实现的性能数据
- 虚线表示响应式实现的性能数据
- 值为0的测试点表示测试失败
- QPS越高表示性能越好,响应时间越低表示性能越好
响应式的优势在高并发、I/O密集型场景下才明显。如果并发不高,同步模式的线程池(通常几十到几百个线程)完全够用
基于Starlight构建 | 主题色: Flexoki | 构建日期: 2026.03.23 | Change Log | Ko-fi