RPC
什么是RPC?
Section titled “什么是RPC?”RPC(Remote Procedure Call): 远程过程调用,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。也就是说两台服务器A,B,一个应用部署在A服务器上,想要调用B服务器上应用提供的方法,由于不在一个内存空间,不能直接调用,需要通过网络来表达调用的语义和传达调用的数据。
RPC协议假定某些传输协议的存在,如TCP或UDP,为通信程序之间携带信息数据。在OSI网络通信模型中,RPC跨越了传输层和应用层。RPC使得开发包括网络分布式多程序在内的应用程序更加容易。现在业界有很多开源的优秀 RPC 框架,例如 Spring Cloud、Dubbo、Thrift 等。
RPC的实现基础
Section titled “RPC的实现基础”- 需要有非常高效的网络通信,比如一般选择Netty作为网络通信框架;
- 需要有比较高效的序列化框架,比如谷歌的Protobuf序列化框架;
- 可靠的寻址方式(主要是提供服务的发现),比如可以使用Zookeeper来注册服务等等;
- 如果是带会话(状态)的RPC调用,还需要有会话和状态保持的功能;
RPC的主要作用
Section titled “RPC的主要作用”- 屏蔽远程调用跟本地调用的区别,让我们感觉就是调用项目内的方法
- 隐藏底层网络通信的复杂性,让我们更专注于业务逻辑
RPC 工作原理
Section titled “RPC 工作原理”RPC的设计由Client,Client stub,Network ,Server stub,Server构成。 其中Client就是用来调用服务的,Cient stub是用来把调用的方法和参数序列化的(因为要在网络中传输,必须要把对象转变成字节),Network用来传输这些信息到Server stub, Server stub用来把这些信息反序列化的,Server就是服务的提供者,最终调用的就是Server提供的方法。
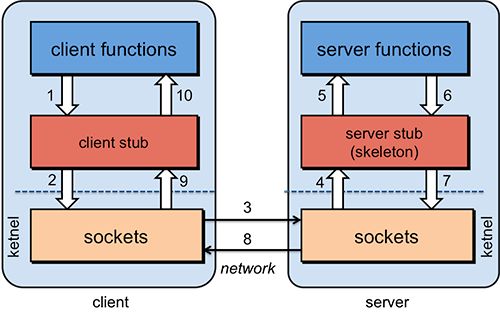
- Client像调用本地服务似的调用远程服务;
- Client stub接收到调用后,将方法、参数序列化
- 客户端通过sockets将消息发送到服务端
- Server stub 收到消息后进行解码(将消息对象反序列化)
- Server stub 根据解码结果调用本地的服务
- 本地服务执行(对于服务端来说是本地执行)并将结果返回给Server stub
- Server stub将返回结果打包成消息(将结果消息对象序列化)
- 服务端通过sockets将消息发送到客户端
- Client stub接收到结果消息,并进行解码(将结果消息反序列化)
- 客户端得到最终结果。
RPC使用了哪些关键技术?
Section titled “RPC使用了哪些关键技术?”- 动态代理。生成Client Stub(客户端存根)和Server Stub(服务端存根)的时候需要用到Java动态代理技术,可以使用JDK提供的原生的动态代理机制,也可以使用开源的:CGLib代理,Javassist字节码生成技术。
- 序列化和反序列化。在网络中,所有的数据都将会被转化为字节进行传送,所以为了能够使参数对象在网络中进行传输,需要对这些参数进行序列化和反序列化操作。
序列化:把对象转换为字节序列的过程称为对象的序列化,也就是编码的过程。反序列化:把字节序列恢复为对象的过程称为对象的反序列化,也就是解码的过程。 目前比较高效的开源序列化框架:如Kryo、FastJson和Protobuf等。
反序列化:把字节序列恢复为对象的过程称为对象的反序列化,也就是解码的过程。 目前比较高效的开源序列化框架:如Kryo、FastJson和Protobuf等。
Dubbo默认使用的是Hessian2.0框架
- NIO通信。出于并发性能的考虑,传统的阻塞式IO显然不太合适,因此我们需要异步的IO,即NIO。Java提供了NIO的解决方案,Java 7 也提供了更优秀的NIO.2支持。可以选择Netty或者MINA来解决NIO数据传输的问题。
- 服务注册中心。可选:Redis、Zookeeper、Consul 、Etcd。一般使用ZooKeeper提供服务注册与发现功能,解决单点故障以及分布式部署的问题(注册中心)。
RPC和Restful的对比
Section titled “RPC和Restful的对比”- 面对对象不同:RPC 更侧重于动作。Restful 的主体是资源。Restful 是面向资源的设计架构,但在系统中有很多对象不能抽象成资源,比如登录,修改密码等而 RPC 可以通过动作去操作资源。所以在操作的全面性上 RPC 大于 Restful。
- 传输效率:RPC 效率更高。RPC使用自定义的 TCP 协议,可以让请求报文体积更小,或者使用 HTTP2 协议,也可以很好的减少报文的体积,提高传输效率。
- 复杂度:RPC实现复杂,流程繁琐。REST 调用及测试都很方便。RPC 实现需要实现编码,序列化,网络传输等。而 Restful 不要关注这些,Restful 实现更简单。
- 灵活性:HTTP 相对更规范,更标准,更通用,无论哪种语言都支持 HTTP 协议。RPC可以实现跨语言调用,但整体灵活性不如 Restful。
- 使用场景: RPC 主要用于公司内部的服务调用,性能消耗低,传输效率高,实现复杂。HTTP 主要用于对外的异构环境,浏览器接口调用,App 接口调用,第三方接口调用等
RPC 框架代表
Section titled “RPC 框架代表”开源社区里有许多优秀的 RPC 框架,比如常用的有 阿里的Dubbo、google的gRPC、Go语言的rpcx、Apache的thrift等,下面简单介绍一下这几款组件。
一个很常被问到的问题,为什么要使用RPC呢?
Section titled “一个很常被问到的问题,为什么要使用RPC呢?”这个从RPC的优点来说就好了
TCP 是有三个特点,面向连接、可靠、基于字节流。
TCP粘包问题: 主要是字节流导致的,字节流可以理解为一个双向的通道里流淌的数据,这个数据其实就是我们常说的二进制数据,简单来说就是一大堆 01 串。纯裸 TCP 收发的这些 01 串之间是没有任何边界的,你根本不知道到哪个地方才算一条完整消息。正因为这个没有任何边界的特点,导致了解析接收到的消息会存在不同的立即。例如当我们选择使用 TCP 发送”夏洛”和”特烦恼”的时候,接收端收到的就是”夏洛特烦恼”,这时候接收端没发区分你是想要表达”夏洛”+“特烦恼”还是”夏洛特”+“烦恼”
纯裸 TCP 是不能直接拿来用的,你需要在这个基础上加入一些自定义的规则,用于区分消息边界。于是我们会把每条要发送的数据都包装一下,比如加入消息头,消息头里写清楚一个完整的包长度是多少,根据这个长度可以继续接收数据,截取出来后它们就是我们真正要传输的消息体。而这里头提到的消息头,还可以放各种东西,比如消息体是否被压缩过和消息体格式之类的,只要上下游都约定好了,互相都认就可以了,这就是所谓的协议。
于是基于 TCP,就衍生了非常多的协议,比如 HTTP 和 RPC。
HTTP 协议(Hyper Text Transfer Protocol),又叫做超文本传输协议。我们用的比较多,平时上网在浏览器上敲个网址就能访问网页,这里用到的就是 HTTP 协议。而 RPC(Remote Procedure Call),又叫做远程过程调用。它本身并不是一个具体的协议,而是一种调用方式。
RPC底层连接形式
Section titled “RPC底层连接形式”以主流的 HTTP/1.1 协议为例,其默认在建立底层 TCP 连接之后会一直保持这个连接(Keep Alive),之后的请求和响应都会复用这条连接。
而 RPC 协议,也跟 HTTP 类似,也是通过建立 TCP 长链接进行数据交互,但不同的地方在于,RPC 协议一般还会再建个连接池,在请求量大的时候,建立多条连接放在池内,要发数据的时候就从池里取一条连接出来,用完放回去,下次再复用。
由于连接池有利于提升网络请求性能,所以不少编程语言的网络库里都会给 HTTP 加个连接池
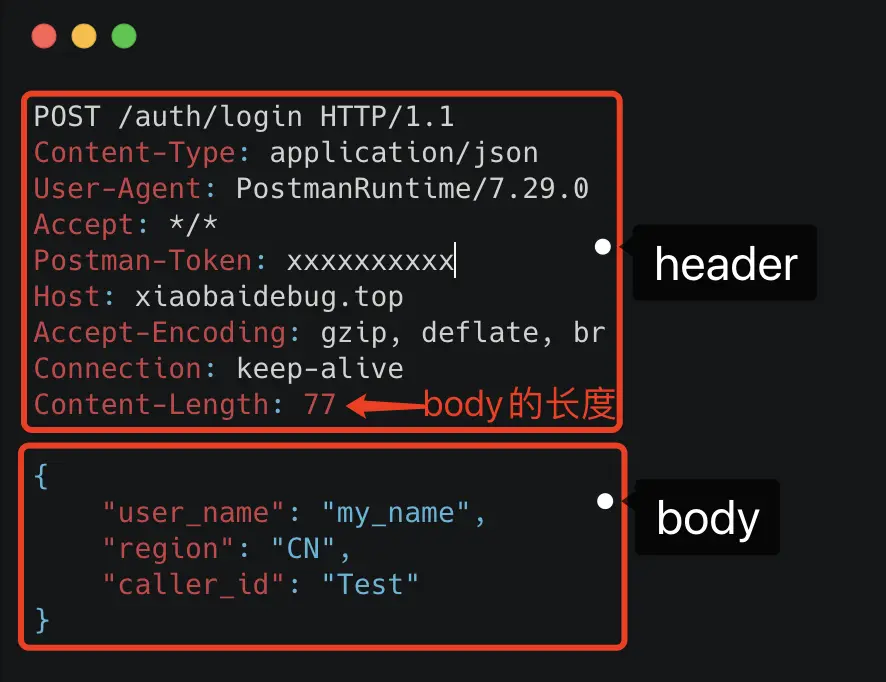
基于 TCP 传输的消息,说到底,无非都是消息头 Header 和消息体 Body。
Header 是用于标记一些特殊信息,其中最重要的是消息体长度。
Body 则是放我们真正需要传输的内容。
对于主流的 HTTP/1.1,虽然它现在叫超文本协议,支持音频视频,但 HTTP 设计初是用于做网页文本展示的,所以它传的内容以字符串为主。Header 和 Body 都是如此
而 RPC,因为它定制化程度更高,可以采用体积更小的 Protobuf 或其他序列化协议去保存结构体数据,同时也不需要像 HTTP 那样考虑各种浏览器行为,比如 302 重定向跳转啥的。因此性能也会更好一些,这也是在公司内部微服务中抛弃 HTTP,选择使用 RPC 的最主要原因。
HTTP/2 在前者的基础上做了很多改进,所以性能可能比很多 RPC 协议还要好,甚至连 gRPC 底层都直接用的 HTTP/2。由于 HTTP/2 是 2015 年出来的。那时候很多公司内部的 RPC 协议都已经跑了好些年了,基于历史原因,一般也没必要去换了。
http2相比于http1.1有哪些优势?
Section titled “http2相比于http1.1有哪些优势?”http1的缺点
Section titled “http1的缺点”- 线头阻塞:方式为,若干个请求排队串行化单线程处理,后面的请求等待前面请求的返回才能获得执行机会,一旦有某请求超时等,后续请求只能被阻塞,毫无办法,也就是人们常说的线头阻塞;
- 没有充分的利用TCP链接: HTTP 1.x 中,如果想并发多个请求,必须使用多个 TCP 链接,且浏览器为了控制资源,还会对单个域名有 6-8个的TCP链接请求限制
http2优点
Section titled “http2优点”- 多路复用:最有价值的优点,解决了线头阻塞的问题,允许单一的http2连接可以发送多重的请求和响应,充分的利用TCP。 使得 资源分域名、雪碧图、内联样式等不再适用。
- header压缩:HTTP2.0可以在客户端和服务器端维护静态字典和动态字典用来压缩和差量更新HTTP头部,大大降低因头部传输产生的流量。非两个字典内的header可以适用哈夫曼压缩方式进行压缩。
- 新的二进制格式:http1.x 是文本格式传输,http2是二进制格式传输。
- 服务端推送:服务器端可以主动向客户端推送资源。
- 纯裸 TCP 是能收发数据,但它是个无边界的数据流,上层需要定义消息格式用于定义消息边界。于是就有了各种协议,HTTP 和各类 RPC 协议就是在 TCP 之上定义的应用层协议。
- RPC 本质上不算是协议,而是一种调用方式,而像 gRPC 和 Thrift 这样的具体实现,才是协议,它们是实现了 RPC 调用的协议。目的是希望程序员能像调用本地方法那样去调用远端的服务方法。同时 RPC 有很多种实现方式,不一定非得基于 TCP 协议。
- 从发展历史来说,HTTP 主要用于 B/S 架构,而 RPC 更多用于 C/S 架构。但现在其实已经没分那么清了,B/S 和 C/S 在慢慢融合。很多软件同时支持多端,所以对外一般用 HTTP 协议,而内部集群的微服务之间则采用 RPC 协议进行通讯。
- RPC 其实比 HTTP 出现的要早,且比目前主流的 HTTP/1.1 性能要更好,所以大部分公司内部都还在使用 RPC。
- HTTP/2.0 在 HTTP/1.1 的基础上做了优化,性能可能比很多 RPC 协议都要好,但由于是这几年才出来的,所以也不太可能取代掉 RPC。
参考:
基于Starlight构建 | 主题色: Flexoki | 构建日期: 2026.05.22 | Change Log | Ko-fi